Model Configuration
FastGPT model configuration guide
Introduction
FastGPT uses the AI Proxy service to connect to different model providers. AI Proxy also provides load balancing, model logging, and analytics dashboards to help you monitor model usage.
Notes:
- Only one speech recognition model can be active at a time, so you only need to configure one.
- The system requires at least one language model and one embedding model to function properly.
Architecture Diagram
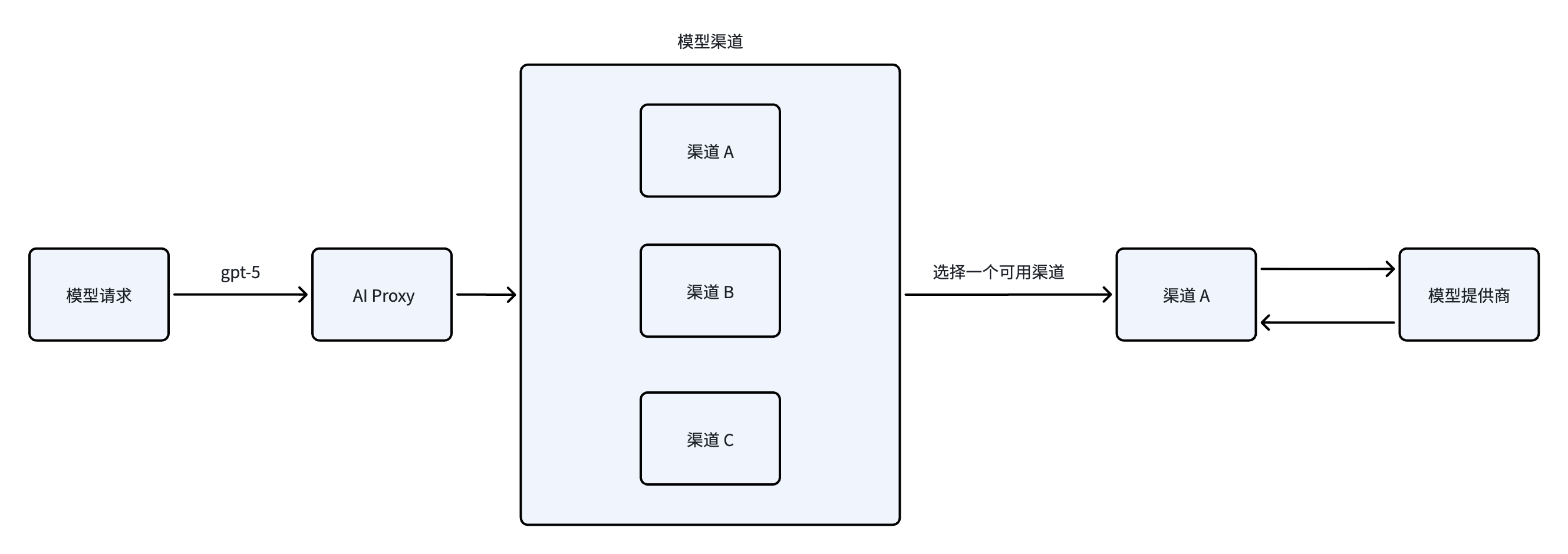
Model Types
- Language Models - Text-based conversations; multimodal models also support image recognition.
- Embedding Models - Index text chunks for semantic text retrieval.
- Rerank Models - Reorder retrieval results to optimize search ranking.
- Text-to-Speech (TTS) - Convert text to audio.
- Speech-to-Text (STT) - Convert audio to text.
Key Terminology
- Model ID: The value of the
modelfield in the API request body. Must be globally unique. - Model Name: The display name of the model, which can be customized.
- Model Channel: The protocol of different model providers, such as OpenAI, Anthropic, Google, etc. Most self-hosted channels follow the OpenAI protocol. A single model can be configured across multiple channels to enable load balancing.
- Custom Request URL / Key: Allows you to bypass Model Channels and send requests directly to a custom endpoint. You need to provide the full request URL and token. Generally not needed (not recommended as it's harder to manage).
Adding Channels and Models
You can configure models from the Account - Model Providers page in FastGPT.
1. Create a Channel
Switch to the Model Channels tab. Note that you can only add models that already exist in Model Configuration. The system only includes mainstream models by default — if you need additional models, add them in Model Configuration first.
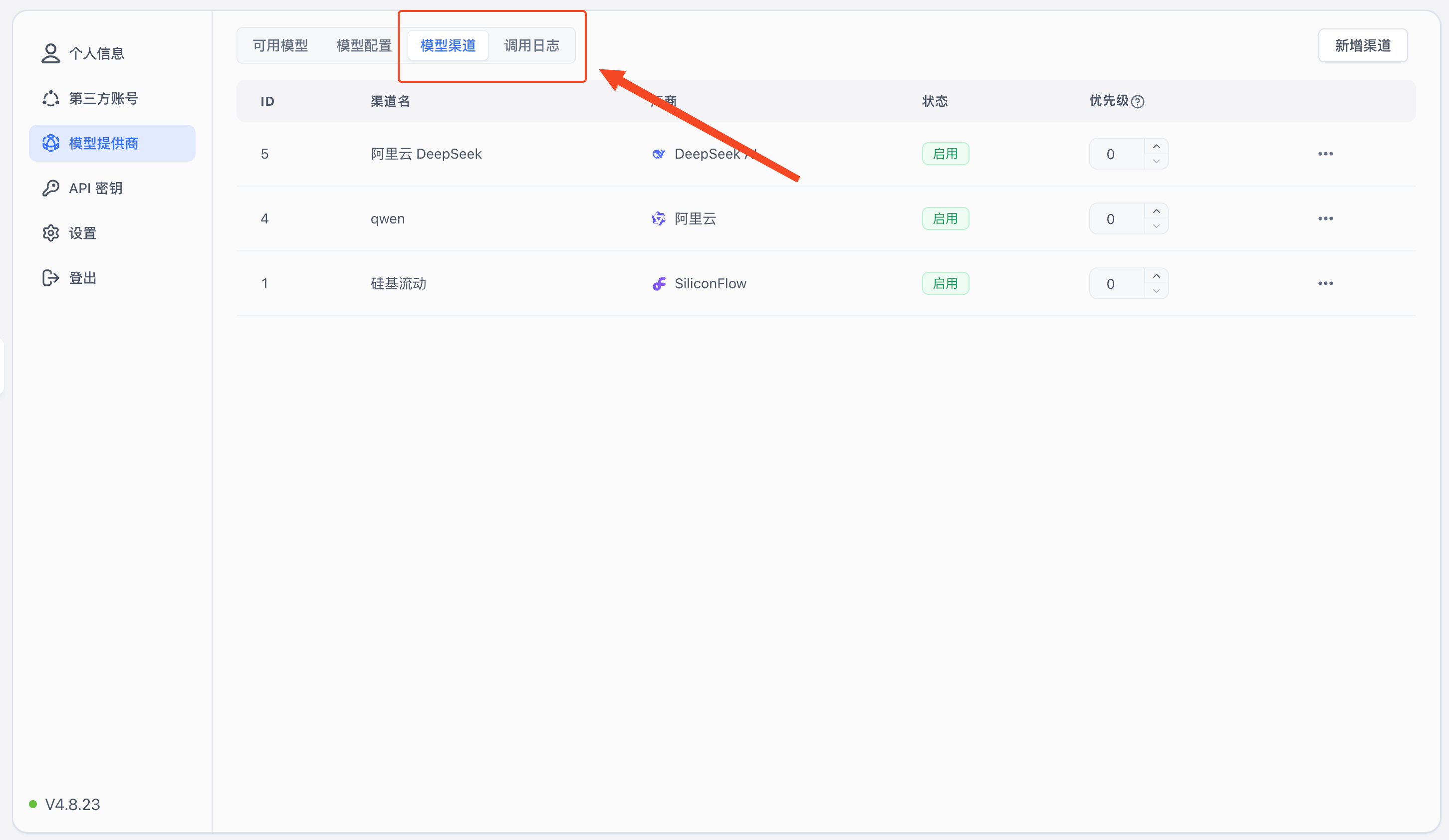
Click "Add Channel" in the top-right corner to open the channel configuration page.
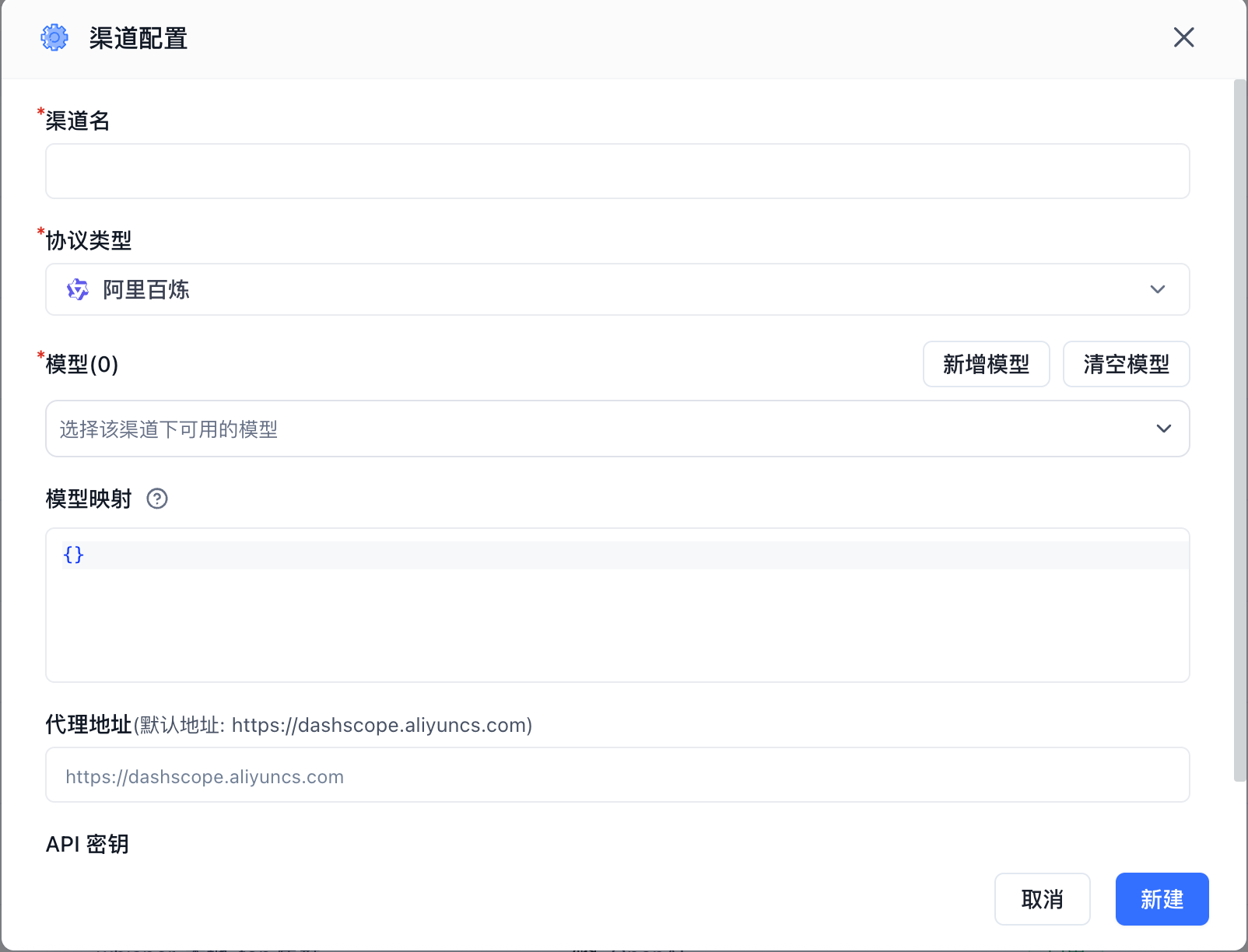
Using Alibaba Bailian models as an example:
- Channel Name: A display label for the channel, used for identification only.
- Protocol Type: The API protocol for the model. Generally, select the provider that offers the model. Most providers support the OpenAI protocol, so you can also choose OpenAI as the protocol type.
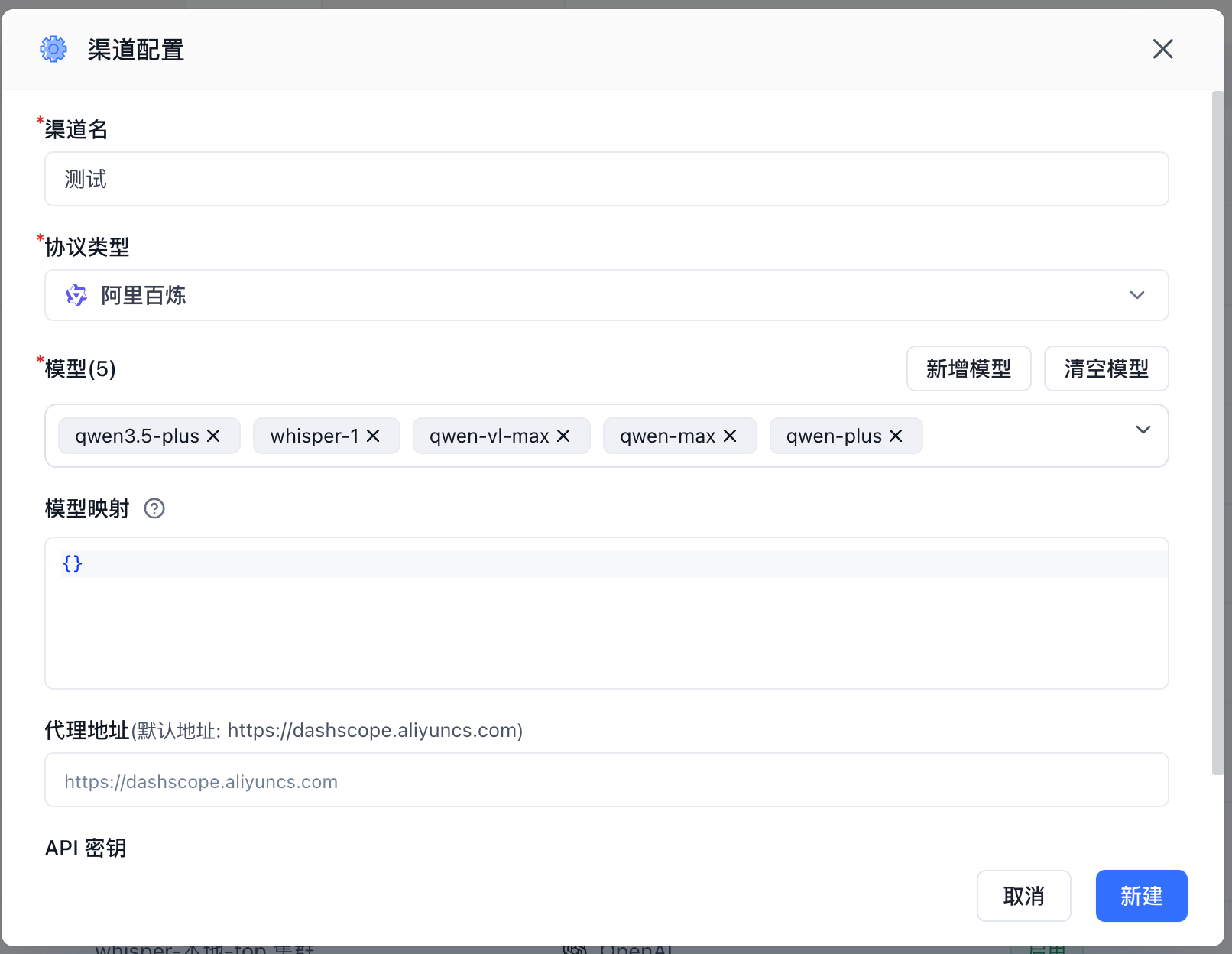
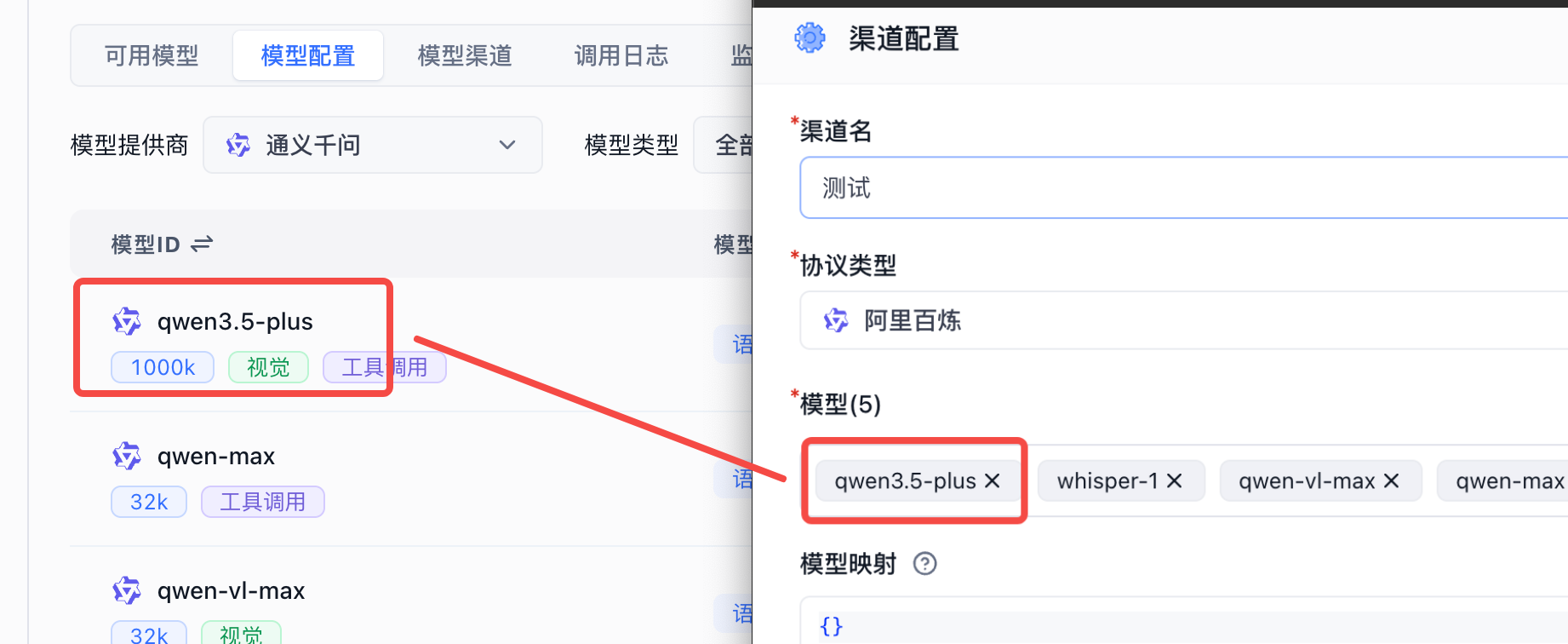
- Models: The specific models available in this channel. The system includes popular models by default. If the model you need isn't in the dropdown, click "Add Model" to add a custom model.
- Model Mapping: Maps the model name in FastGPT requests to the actual model name at the provider. For example:
{
"gpt-4o-test": "gpt-4o"
}In FastGPT, the model is gpt-4o-test, and requests to AI Proxy also use gpt-4o-test. When AI Proxy forwards the request upstream, the actual model value becomes gpt-4o.
- Proxy URL: Do not enter the full model request URL. Enter the
BaseUrlinstead, and check whether/v1needs to be appended. - API Key: The API credentials obtained from the model provider. Some providers require multiple keys — follow the on-screen prompts to enter them.
Click "Add" to save. The new channel will appear under "Model Channels".
2. Channel Testing
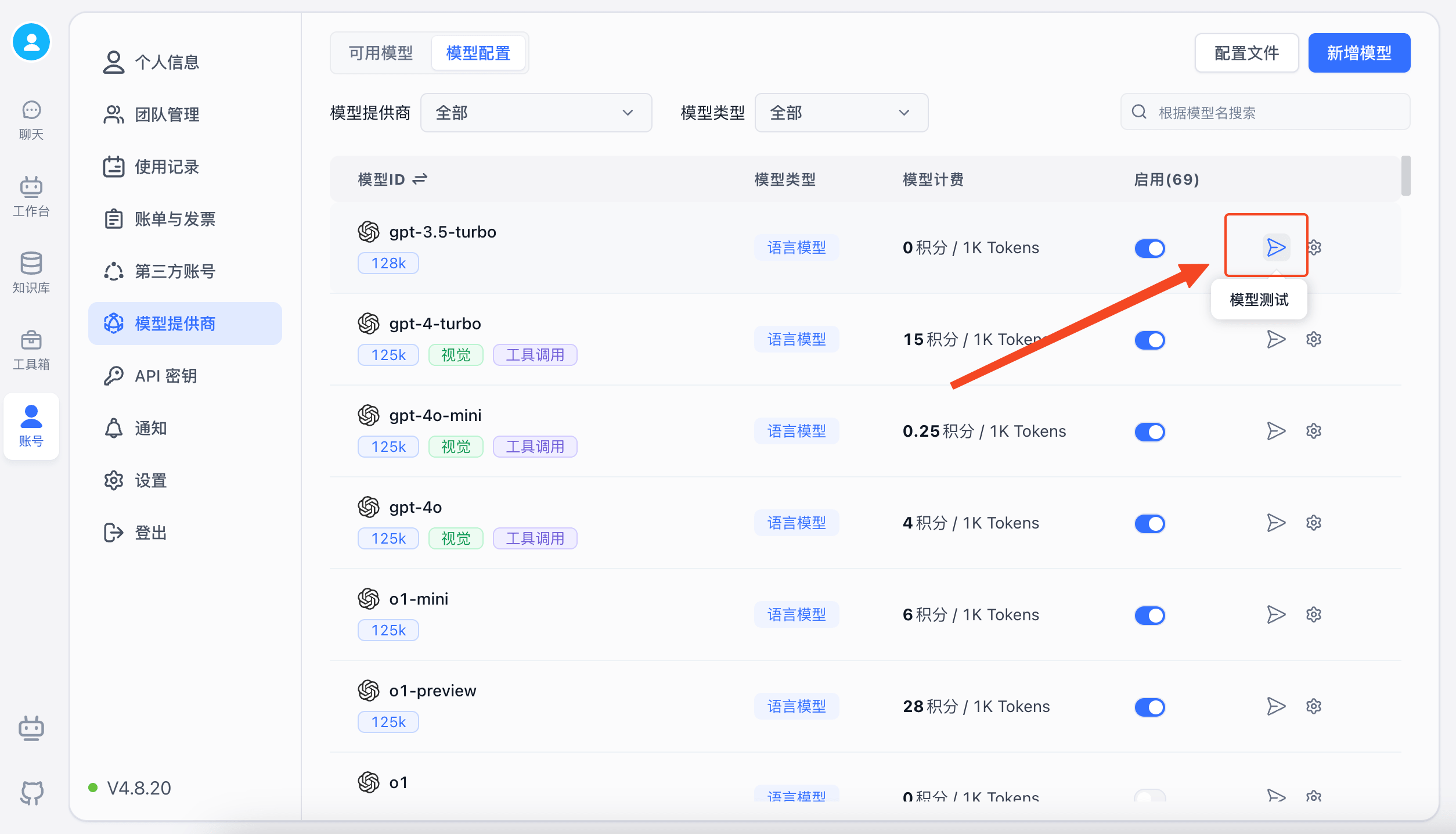
You can test the channel to verify that the configured models are working properly.
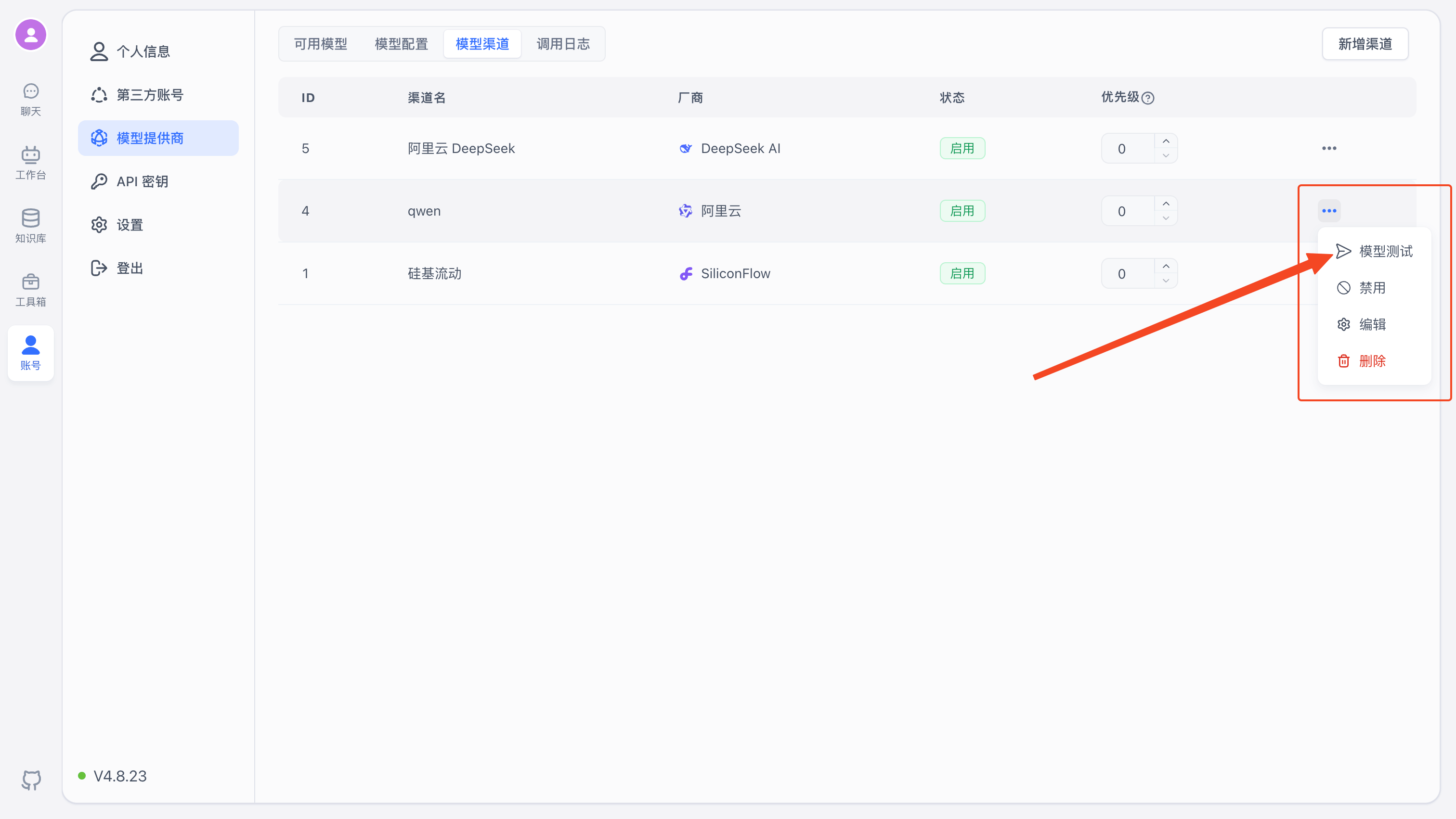
Click "Model Test" to see the list of configured models, then click "Start Test".
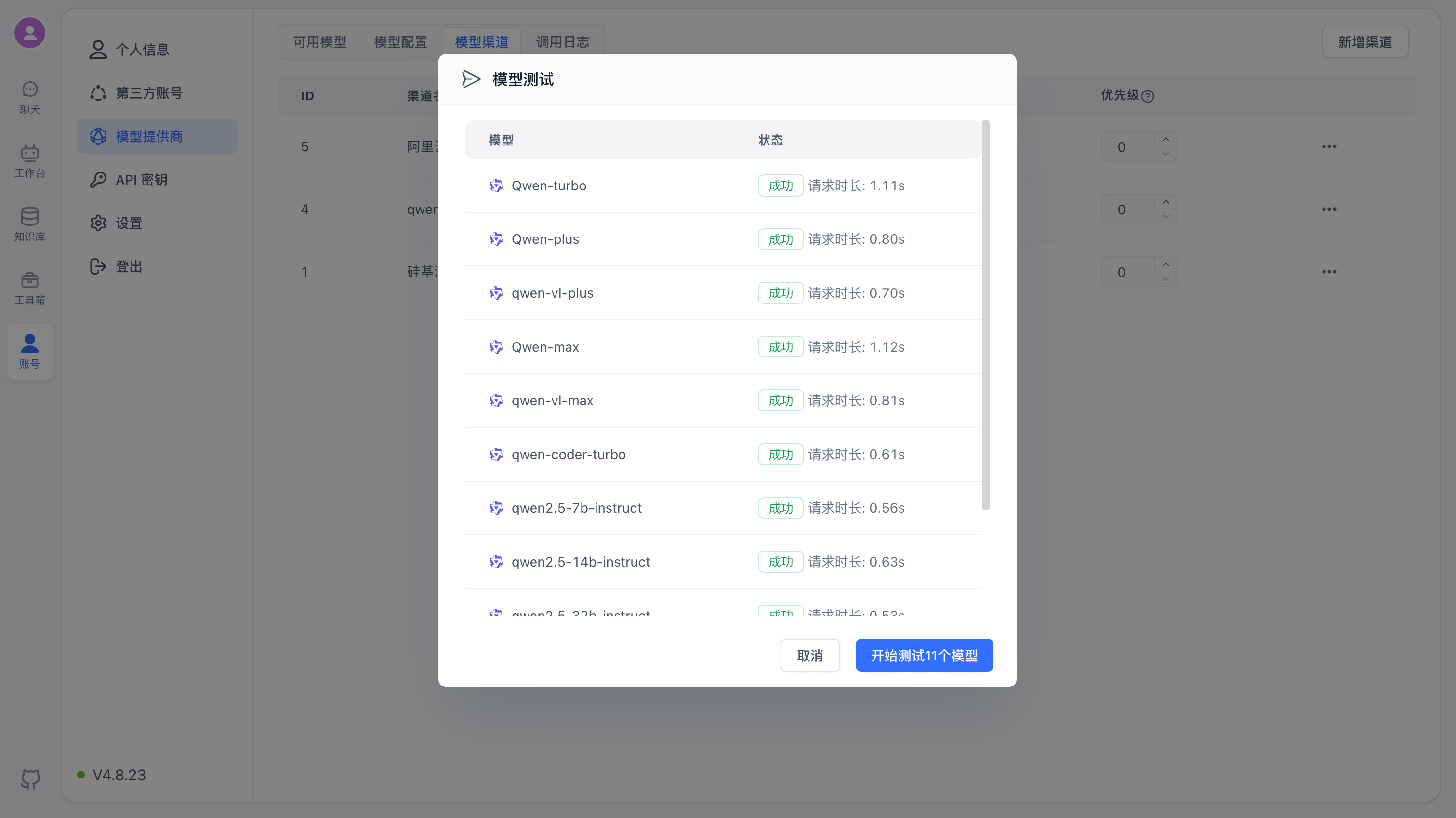
Once testing completes, you'll see the results and response times for each model.
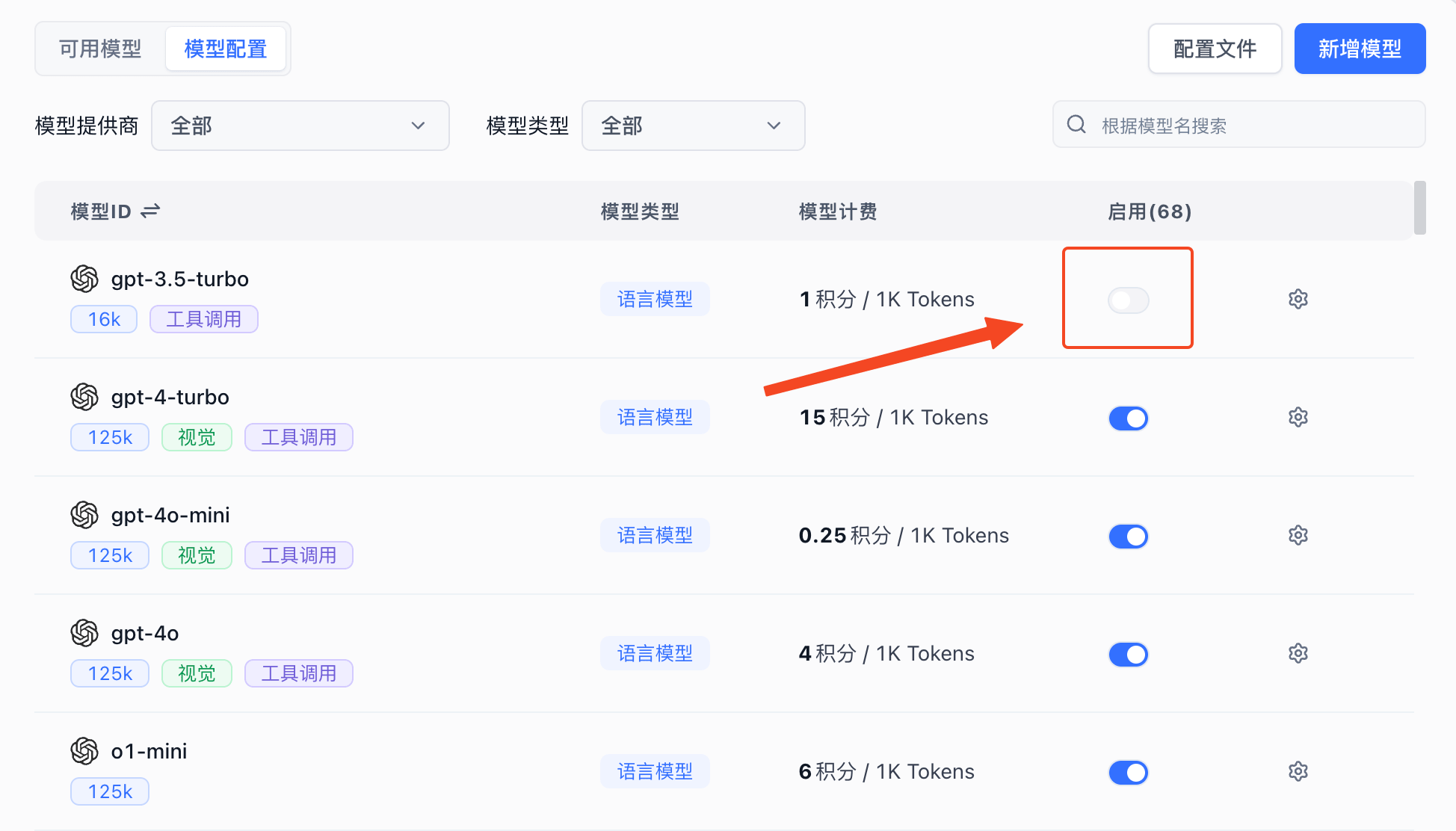
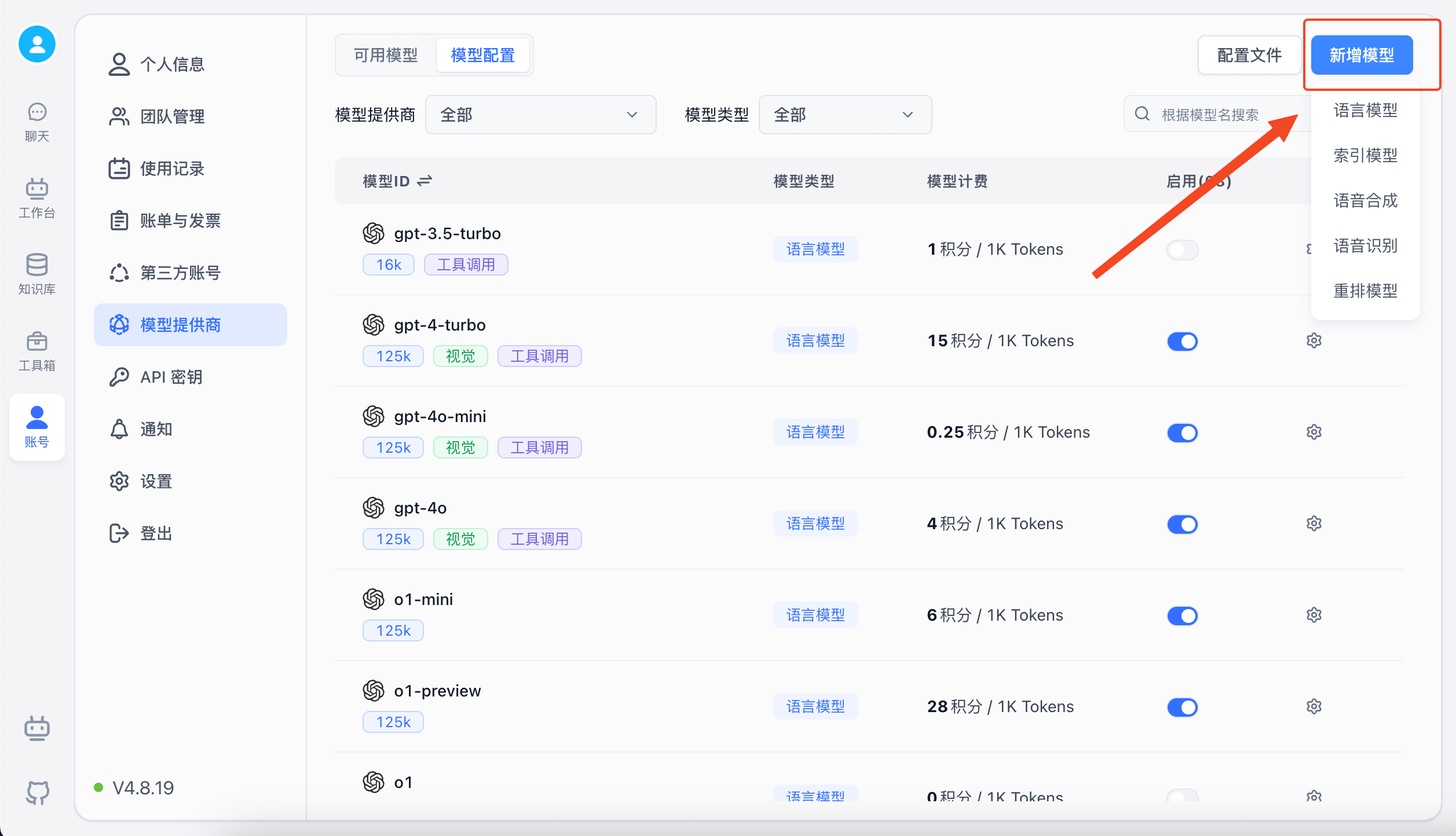
3. Enable Models
The system includes models from major providers by default. If you're not familiar with the configuration, simply click Enable. The Model ID corresponds to the Model in Model Channels.
Click "Enable" to activate the model.
| Enable Models | Model ID Mapping |
|---|---|
 |  |
4. Test Models
FastGPT provides simple tests for each model type on the UI to verify that models are working correctly. Each test sends an actual request using a template.
Model Configuration
Edit Model Configuration
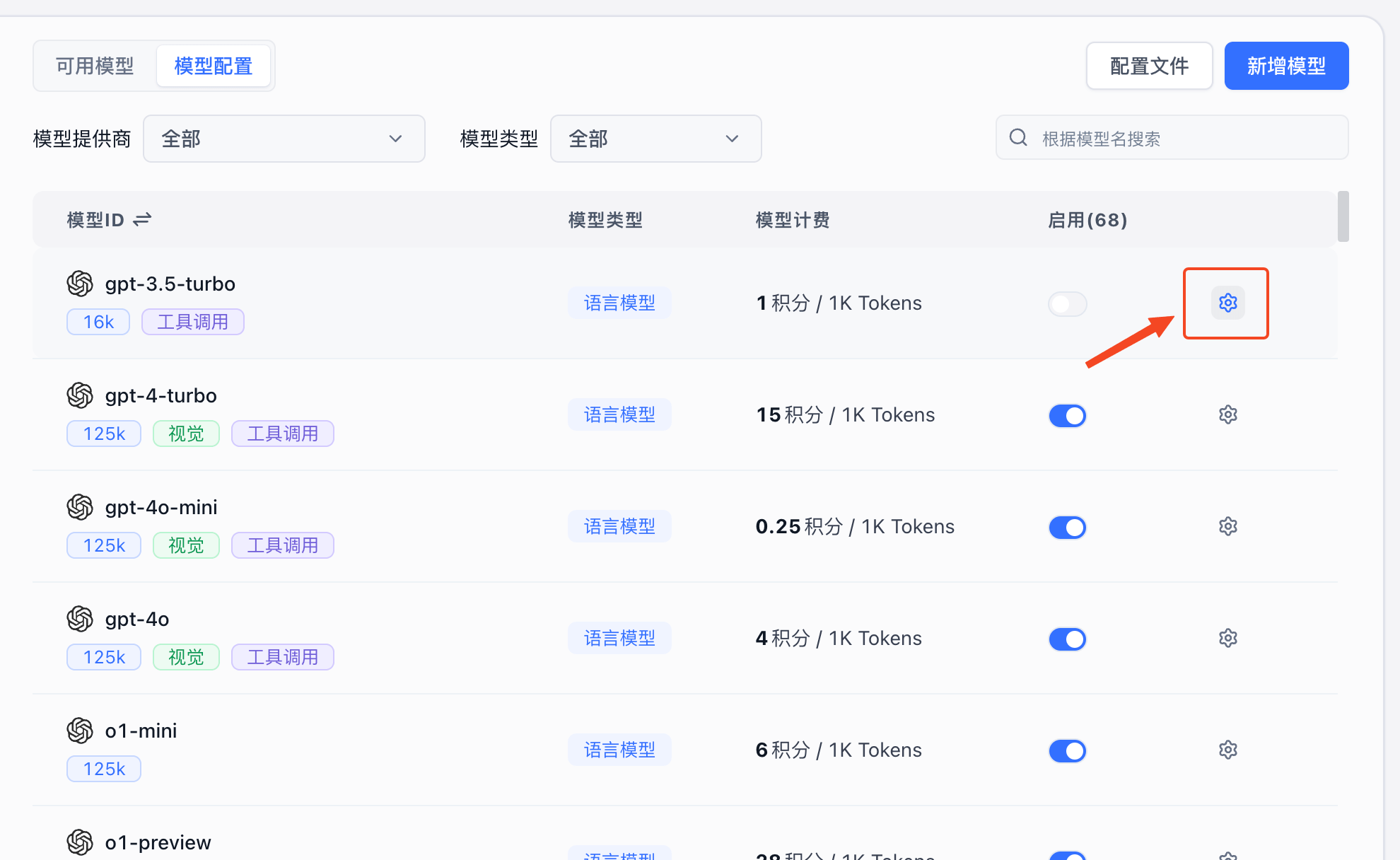
Click the gear icon next to a model to open its configuration. Different model types have different configuration options.
 | 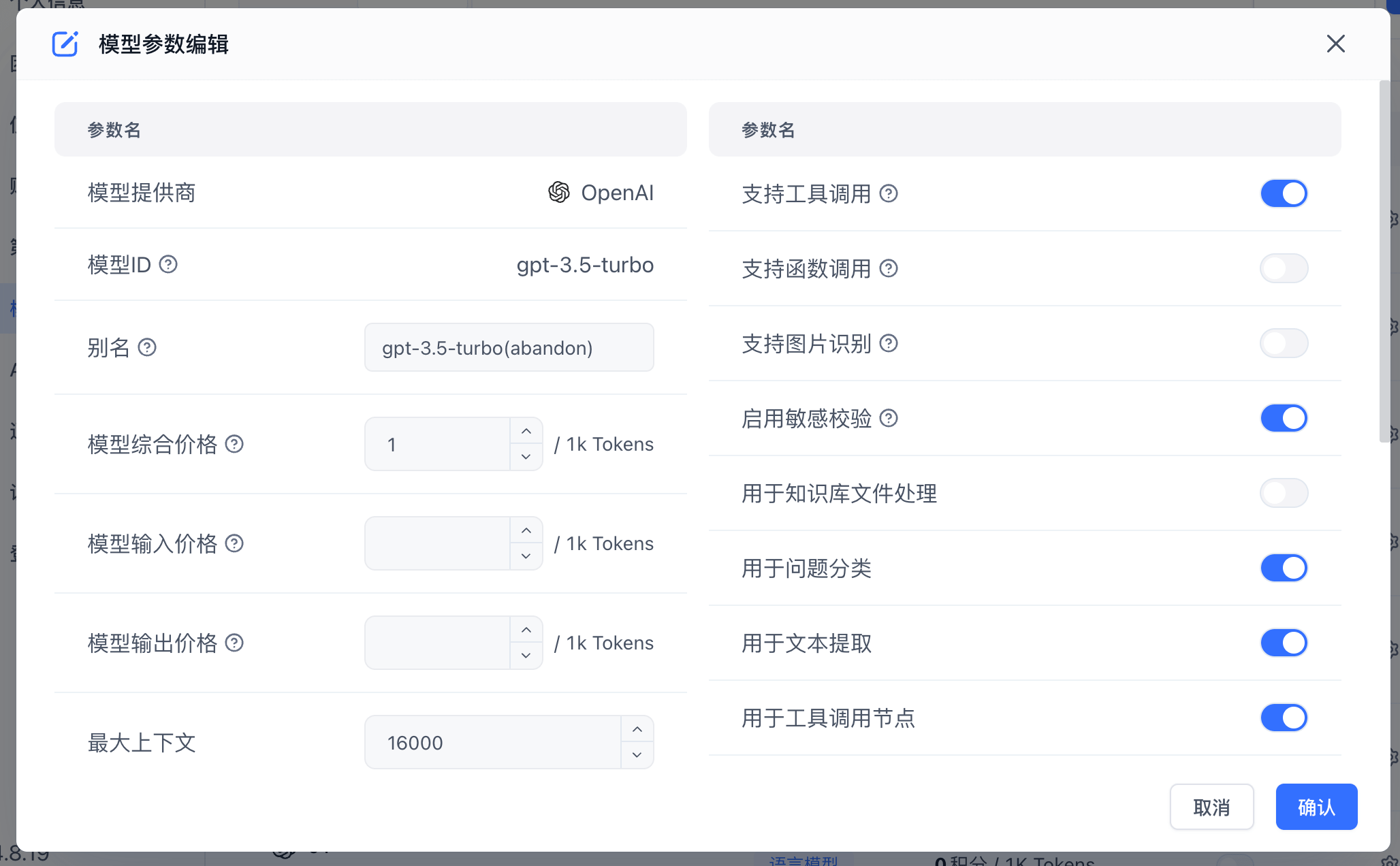 |
Add a Custom Model
If the built-in models don't meet your needs, you can add custom models. If the Model ID matches an existing built-in model ID, it will be treated as a modification rather than a new model.
- Add via Form
 | 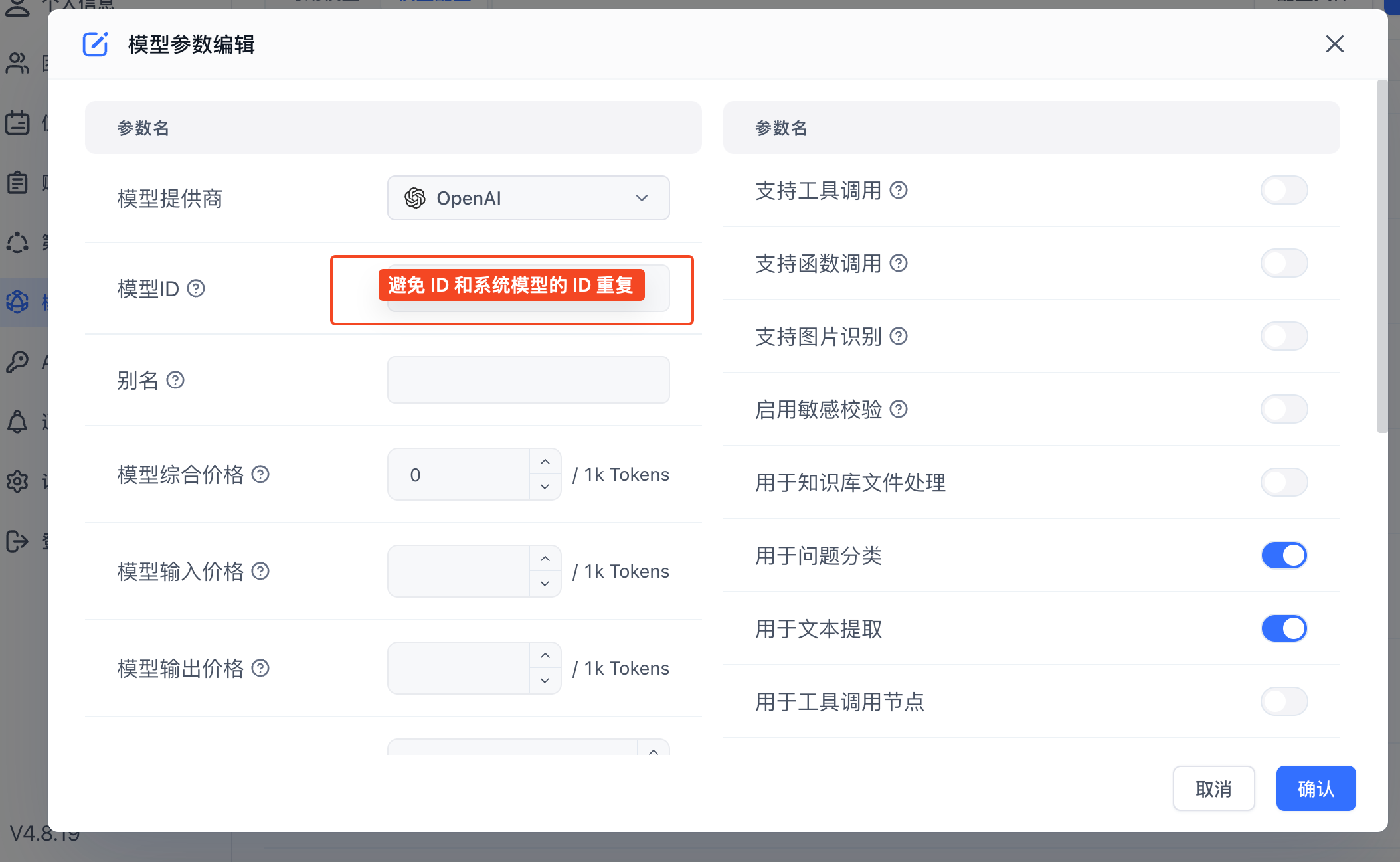 |
- Add via Configuration File
If you find it tedious to configure models through the UI, you can use a configuration file instead. This is also useful for quickly replicating the configuration from one system to another.
 | 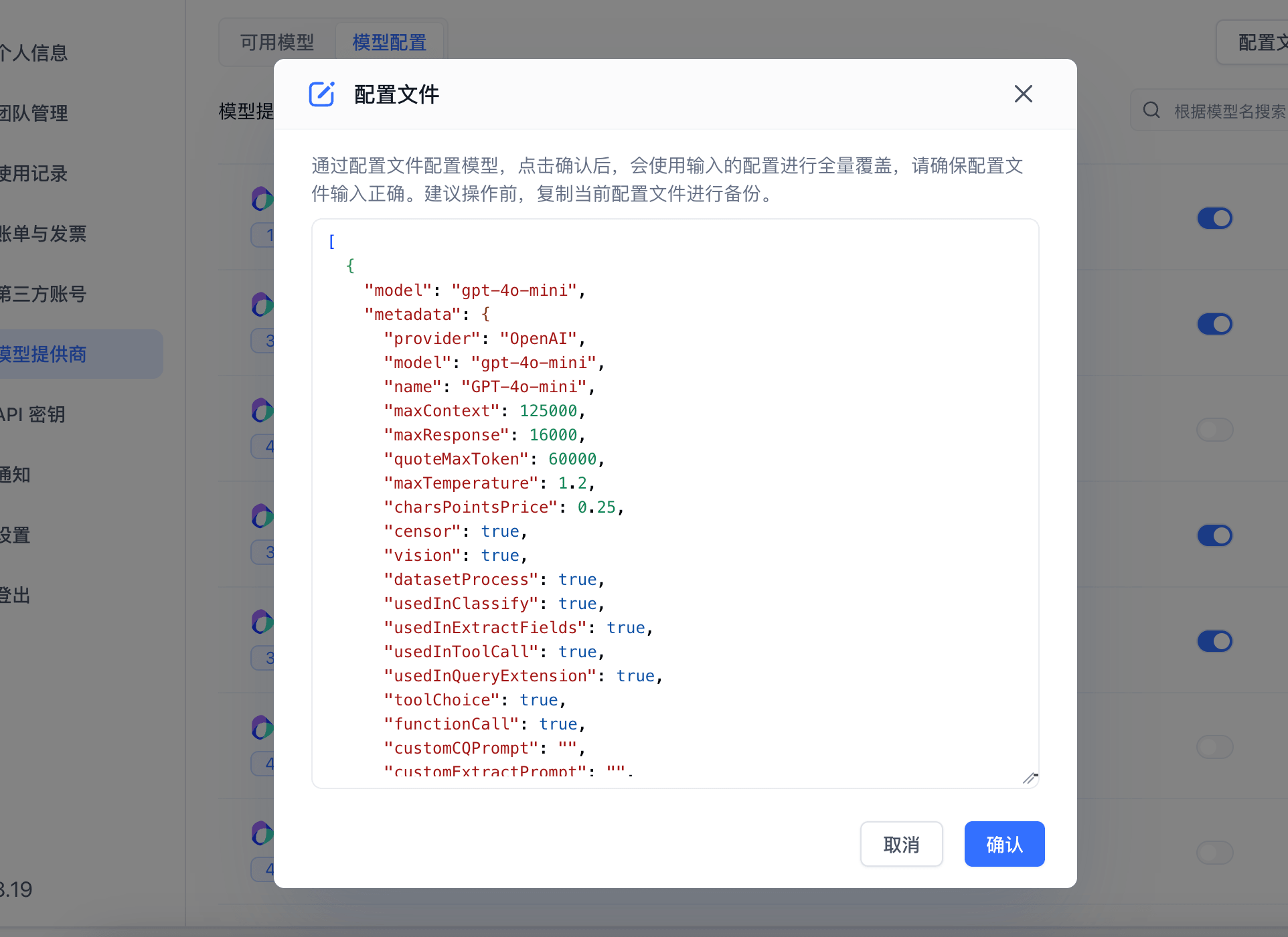 |
Other
Channel Priority
Range: 1–100. Higher values are prioritized.
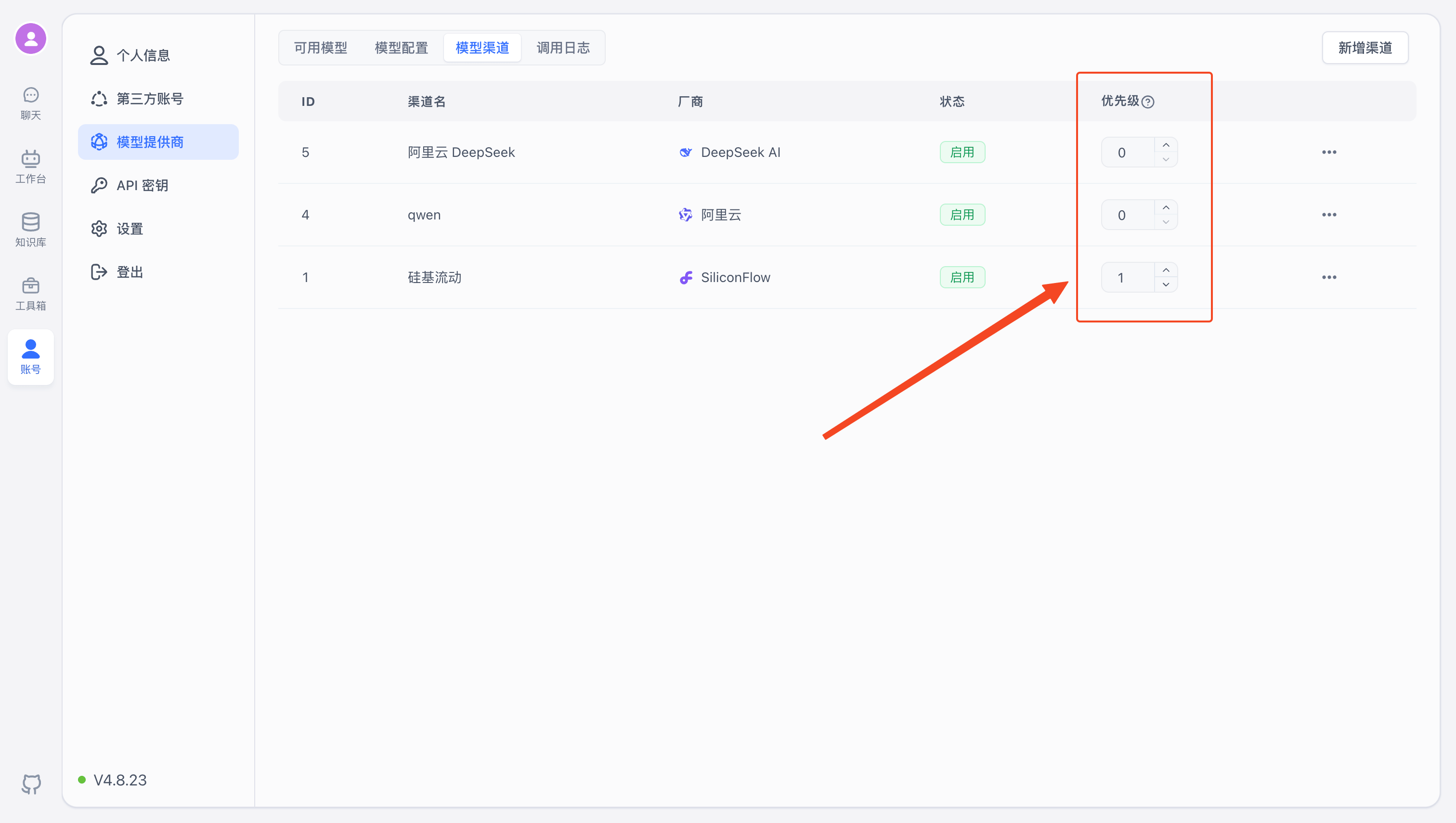
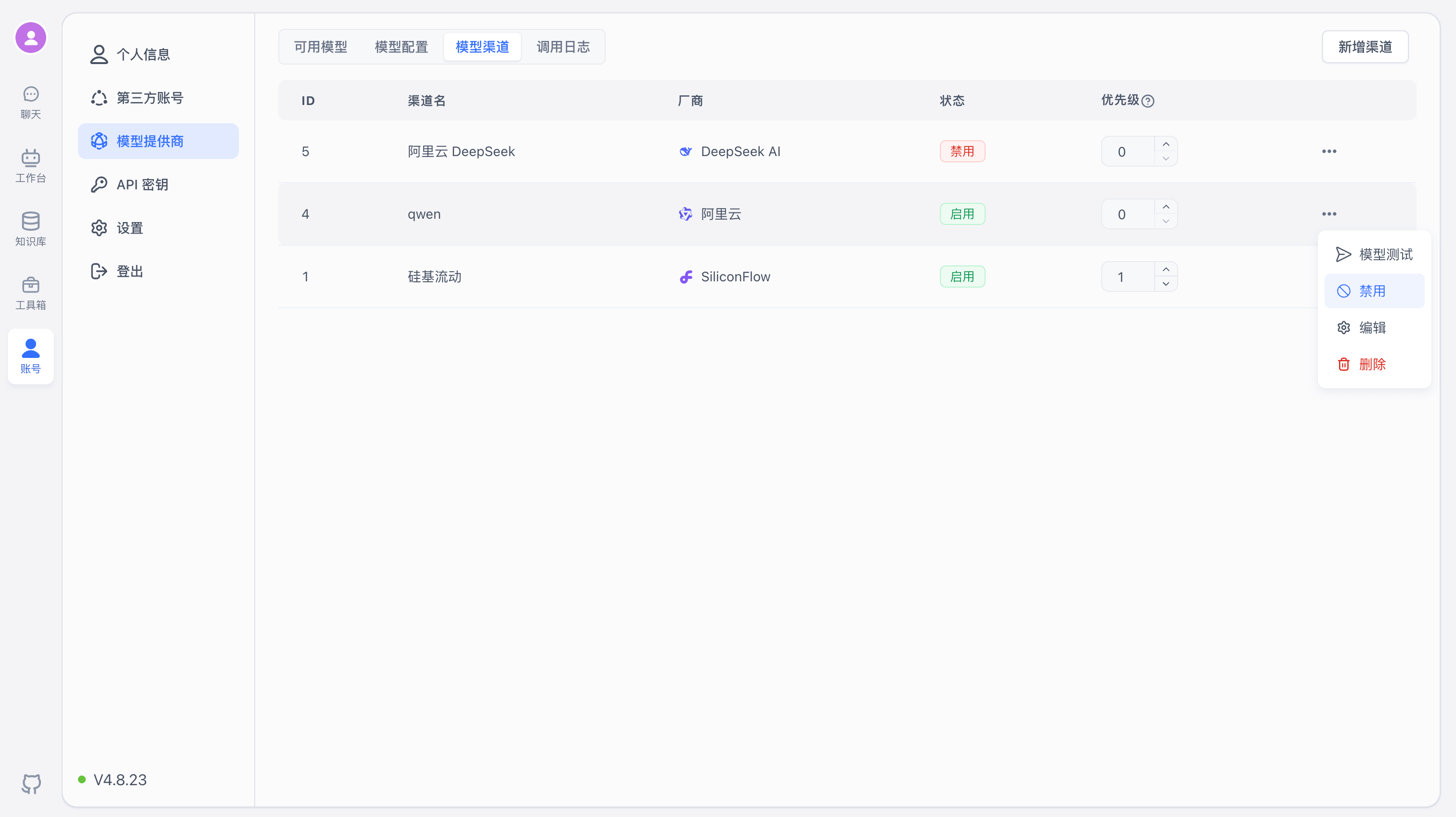
Enable / Disable Channels
In the control menu on the right side of each channel, you can enable or disable it. Disabled channels will no longer serve model requests.
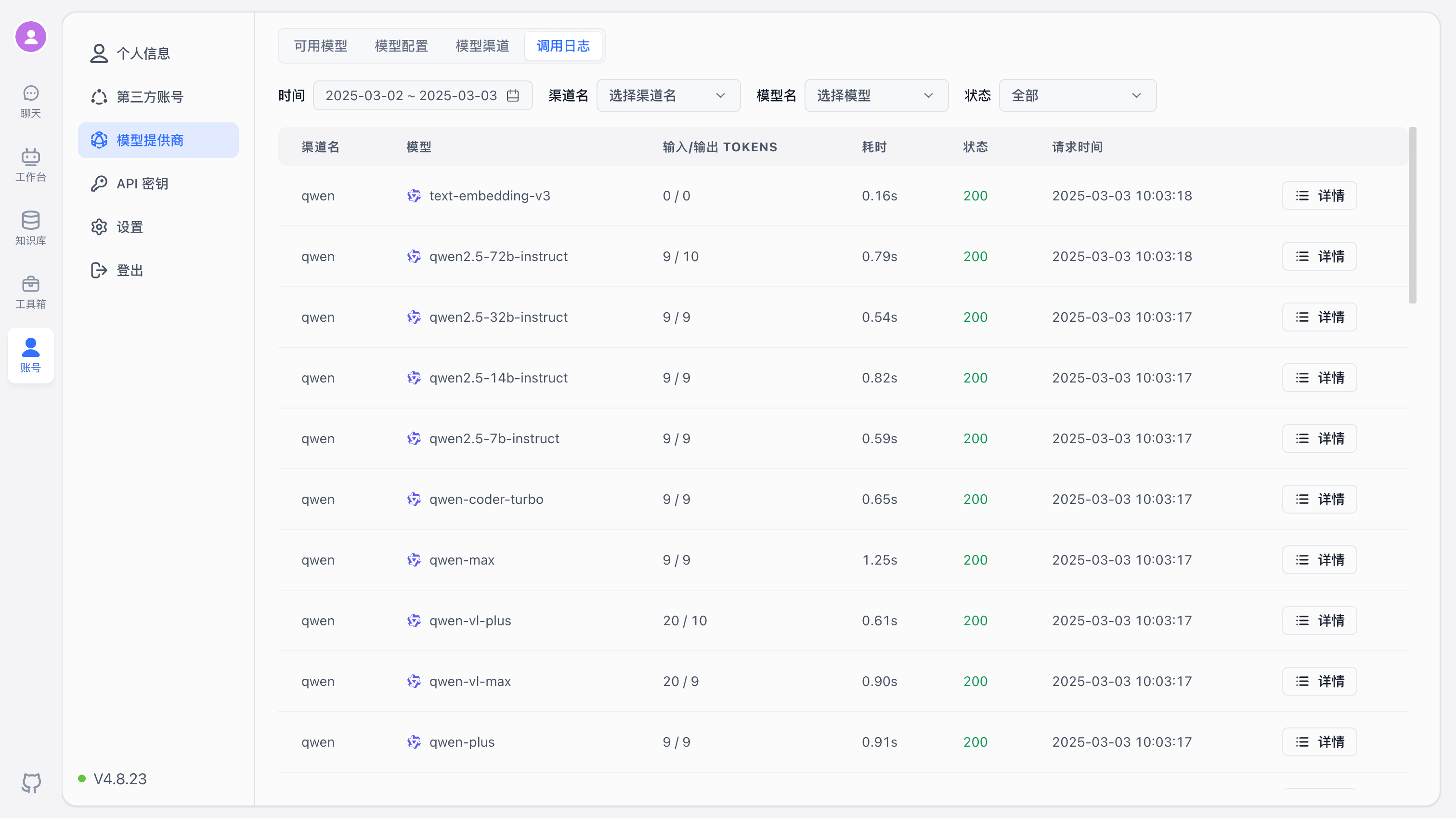
Model Call Logs
Model calls made through channels are logged on the Call Logs page. Logs include input/output tokens, request time, latency, request URL, and more. Failed requests show detailed parameters and error messages for debugging, but logs are retained for only 1 hour by default (configurable via environment variables).
Self-Hosted Models
See the ReRank model deployment tutorial
Custom Request URL
If you set a custom request URL, requests will bypass Model Channels and be sent directly to the specified endpoint. You must provide the full request URL, for example:
- LLM: [host]/v1/chat/completions
- Embedding: [host]/v1/embeddings
- STT: [host]/v1/audio/transcriptions
- TTS: [host]/v1/audio/speech
- Rerank: [host]/v1/rerank
The custom request key is included as the Authorization: Bearer xxx header when sending requests to the custom URL.
All endpoints follow the OpenAI model format. Refer to the OpenAI API documentation for details.
Since OpenAI does not provide a Rerank model, the Rerank endpoint follows the Cohere format. See request examples
Adding Model Presets
You can find model provider configuration files in the modules/model/provider directory of the FastGPT-plugin project and add model configurations there. Make sure the model field is unique across all models. For field descriptions, refer to Model Configuration Fields.
Migrating from OneAPI to AI Proxy
If you were using OneAPI in an older version, you can migrate your channel configuration to AI Proxy using a script.
Send the following HTTP request from any terminal. Replace {{host}} with the AI Proxy address and {{admin_key}} with the ADMIN_KEY value in AI Proxy.
The dsn parameter in the request body is the MySQL connection string for OneAPI.
curl --location --request POST '{{host}}/api/channels/import/oneapi' \
--header 'Authorization: Bearer {{admin_key}}' \
--header 'Content-Type: application/json' \
--data-raw '{
"dsn": "mysql://root:s5mfkwst@tcp(dbconn.sealoshzh.site:33123)/mydb"
}'A successful response will return "success": true.
Note that the migration script performs a simple data mapping — it primarily transfers proxy URLs, models, and API keys. Manual verification after migration is recommended.
File Updated