知识库
API 文件库
FastGPT API 文件库功能介绍和使用方式
 |  |
背景
目前 FastGPT 支持本地文件导入,但是很多时候,用户自身已经有了一套文档库,如果把文件重复导入一遍,会造成二次存储,并且不方便管理。因为 FastGPT 提供了一个 API 文件库的概念,可以通过简单的 API 接口,去拉取已有的文档库,并且可以灵活配置是否导入。
API 文件库能够让用户轻松对接已有的文档库,只需要按照 FastGPT 的 API 文件库规范,提供相应文件接口,然后将服务接口的 baseURL 和 token 填入知识库创建参数中,就能直接在页面上拿到文件库的内容,并选择性导入
如何使用 API 文件库
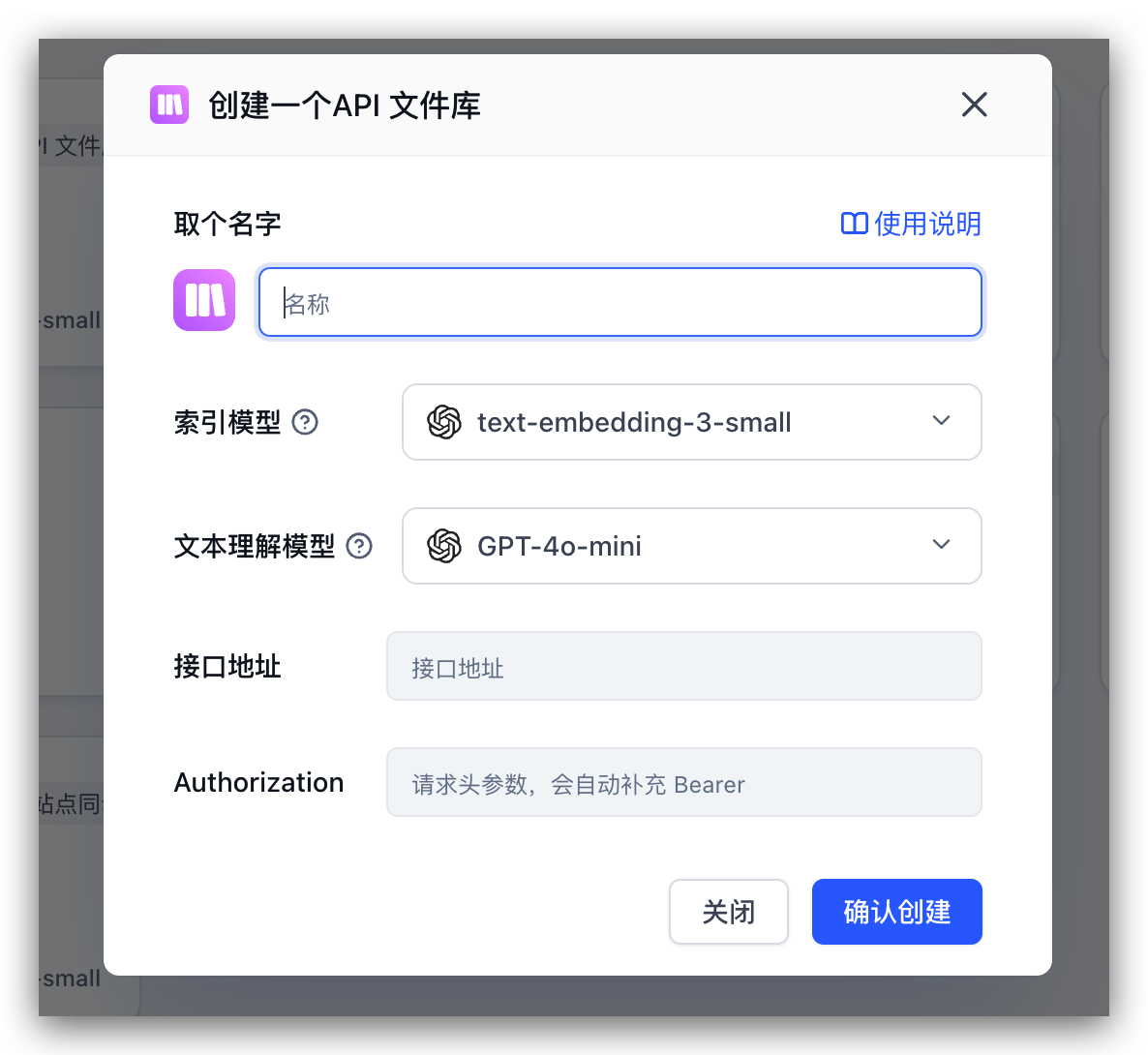
创建知识库时,选择 API 文件库类型,然后需要配置两个关键参数:文件服务接口的 baseURL 和用于身份验证的请求头信息。只要提供的接口规范符合 FastGPT 的要求,系统就能自动获取并展示完整的文件列表,可以根据需要选择性地将文件导入到知识库中。
你需要提供三个参数:
- baseURL: 文件服务接口的 baseURL
- authorization: 用于身份验证的请求头信息,实际请求格式为
Authorization: Bearer <token> - basePath: 可选,根目录路径,用于指定文件树的起始位置
接口规范
接口响应格式:
type ResponseType = {
success: boolean;
message: string;
data: any;
}数据类型:
// 文件列表中,单项的文件类型
type FileListItem = {
id: string;
parentId: string | null;
name: string;
type: 'file' | 'folder';
updateTime: Date;
createTime: Date;
hasChild?: boolean; // 可选,是否有子节点,默认 folder 类型为 true
}1. 获取文件树
- parentId - 父级 id,可选。如果不传或传 null,则使用配置的 basePath 作为根目录
- searchKey - 检索词,可选
curl --location --request POST '{{baseURL}}/v1/file/list' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
--data-raw '{
"parentId": null,
"searchKey": ""
}'{
"success": true,
"message": "",
"data": [
{
"id": "xxxx",
"parentId": "xxxx",
"type": "file",
"name":"test.json",
"updateTime":"2024-11-26T03:05:24.759Z",
"createTime":"2024-11-26T03:05:24.759Z",
"hasChild": false
}
]
}2. 获取单个文件内容(文本内容或访问链接)
curl --location --request GET '{{baseURL}}/v1/file/content?id=xx' \
--header 'Authorization: Bearer {{authorization}}'{
"success": true,
"message": "",
"data": {
"title": "文档标题",
"content": "FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景!\n"
}
}- title - 文件标题,可选。用于显示文件名称,如果不提供,系统会尝试从
previewUrl中解析文件名。 - content - 文件的文本内容,可选。直接返回文件的完整文本内容,系统会直接使用该内容进行索引和检索。
- previewUrl - 文件的访问链接,可选。提供一个可访问的文件 URL,系统会自动请求该地址下载文件并提取内容。支持各种文件格式(如 PDF、Word、Markdown 等)。
重要说明:
content和previewUrl二选一返回,必须至少返回其中一个,否则会报错。- 如果同时返回
content和previewUrl,则content优先级更高,系统会直接使用content的内容。 - 返回
previewUrl时,系统会访问该链接进行文档内容读取和解析,并会缓存解析结果以提高性能。
3. 获取文件阅读链接(用于查看原文)
id 为文件的 id。
curl --location --request GET '{{baseURL}}/v1/file/read?id=xx' \
--header 'Authorization: Bearer {{authorization}}'{
"success": true,
"message": "",
"data": {
"url": "xxxx"
}
}- url - 文件访问链接,拿到后会自动打开。
4. 获取文件详情
id 为文件的 id。
curl --location --request GET '{{baseURL}}/v1/file/detail?id=xx' \
--header 'Authorization: Bearer {{authorization}}'{
"success": true,
"message": "",
"data": {
"id": "xxxx",
"name": "test.json",
"parentId": "xxxx",
"type": "file",
"updateTime": "2024-11-26T03:05:24.759Z",
"createTime": "2024-11-26T03:05:24.759Z"
}
}- id - 文件 id
- name - 文件名称
- parentId - 父级 id,null 表示根目录
- type - 文件类型,file 或 folder
- updateTime - 更新时间
- createTime - 创建时间
在 GitHub 上编辑
文件更新时间